Memory Systems for Legal AI
Memory allows us to maintain a persistent map of the key relationships in a document. That may be, which parties are referenced in each clause, or which clauses share a similar function, and so on.
Let's say we want to apply this information. We ask the AI to adjust the conditions for somebody to become a trustee.
Typically, it would run a set of searches to select the relevant paragraphs to change. This might be search utilising the text in each clause, or a set of word embeddings, or both.
In our instance, because we maintain a persistent memory, the LLM can also check our existing node for "trustee". It then checks everything connected to "trustee" by some kind of relationship. This is visualised below.
So, rather than the LLM constructing both relationships and changes at runtime, it only has to construct the changes. Due to how LLMs work, this is both quicker, as well as more performant, especially with regards to highly complex and interconnected documents.
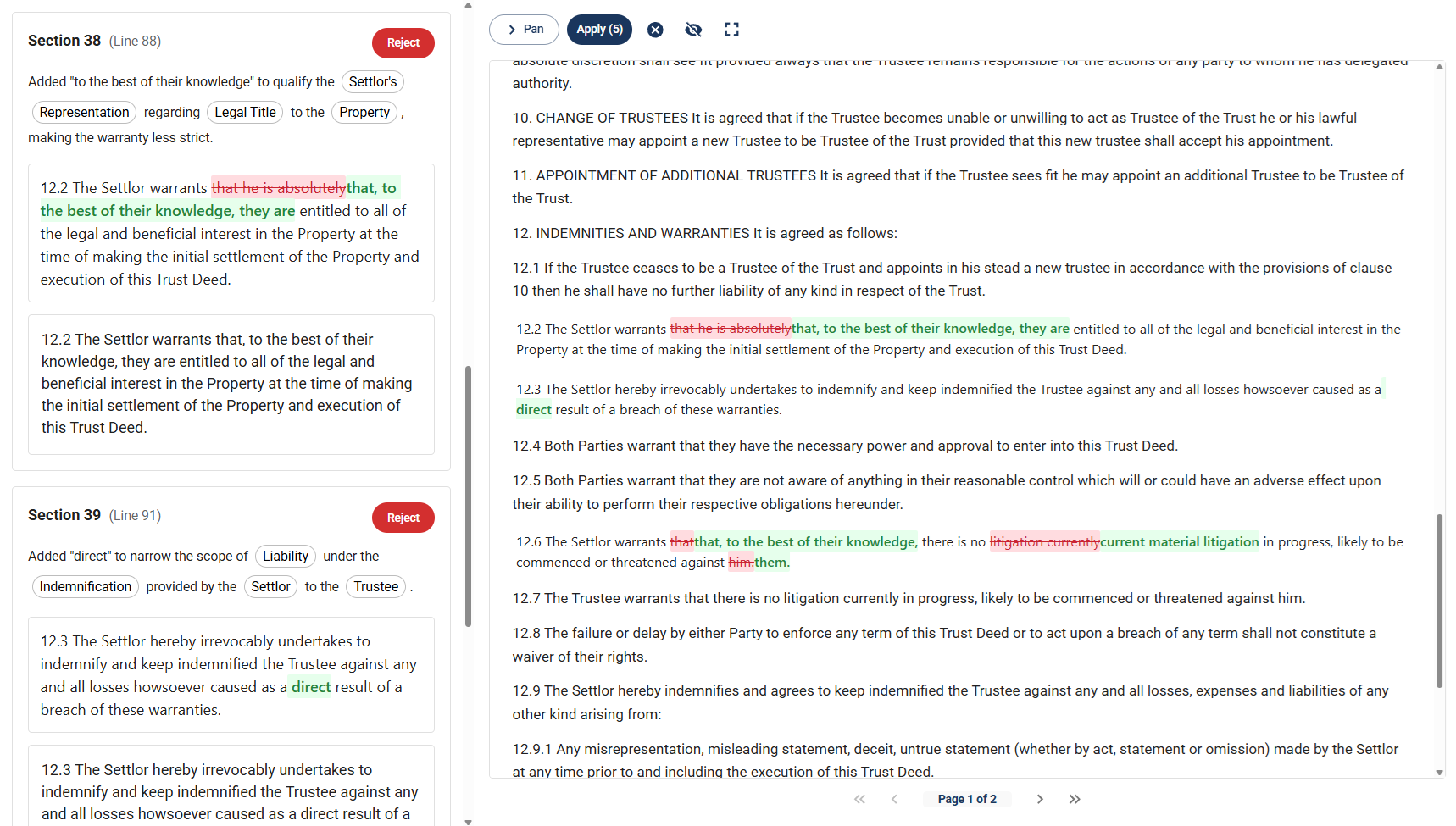
In the screenshot below, you can see how the AI references our nodes in the explanation. The explanation is still in natural language, but it explicitly references the underlying legal structures that were invoked.
Downstream, this also allows us to provide exact textual references from your documents, making human evaluation quicker.
We can also attune the way we utilise our knowledge graph to the type of task we are attempting to achieve, from simple style changes, to deep multi-step analysis. In particular, we often talk about the importance of cascading changes through a legal document: ensuring that any clause we touch accounts for any further downstream changes to the document. A well curated memory system is naturally suited to solving this problem.
This also addresses governance when editing documents with AI tools. By procedurally constraining our LLM to our memory, it is less likely to hallucinate a change, and we can provide more specific reasoning chains for verification systems, both manual and automated.
To conclude, this goes beyond labelling data. We are combining firm rules with versioning and memory for agents. The memory layer lends itself to transparent workflows, suitable for legal use by skilled practitioners.